Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, Ying Shan
Computer Vision and Pattern Recognition(CVPR), 2024
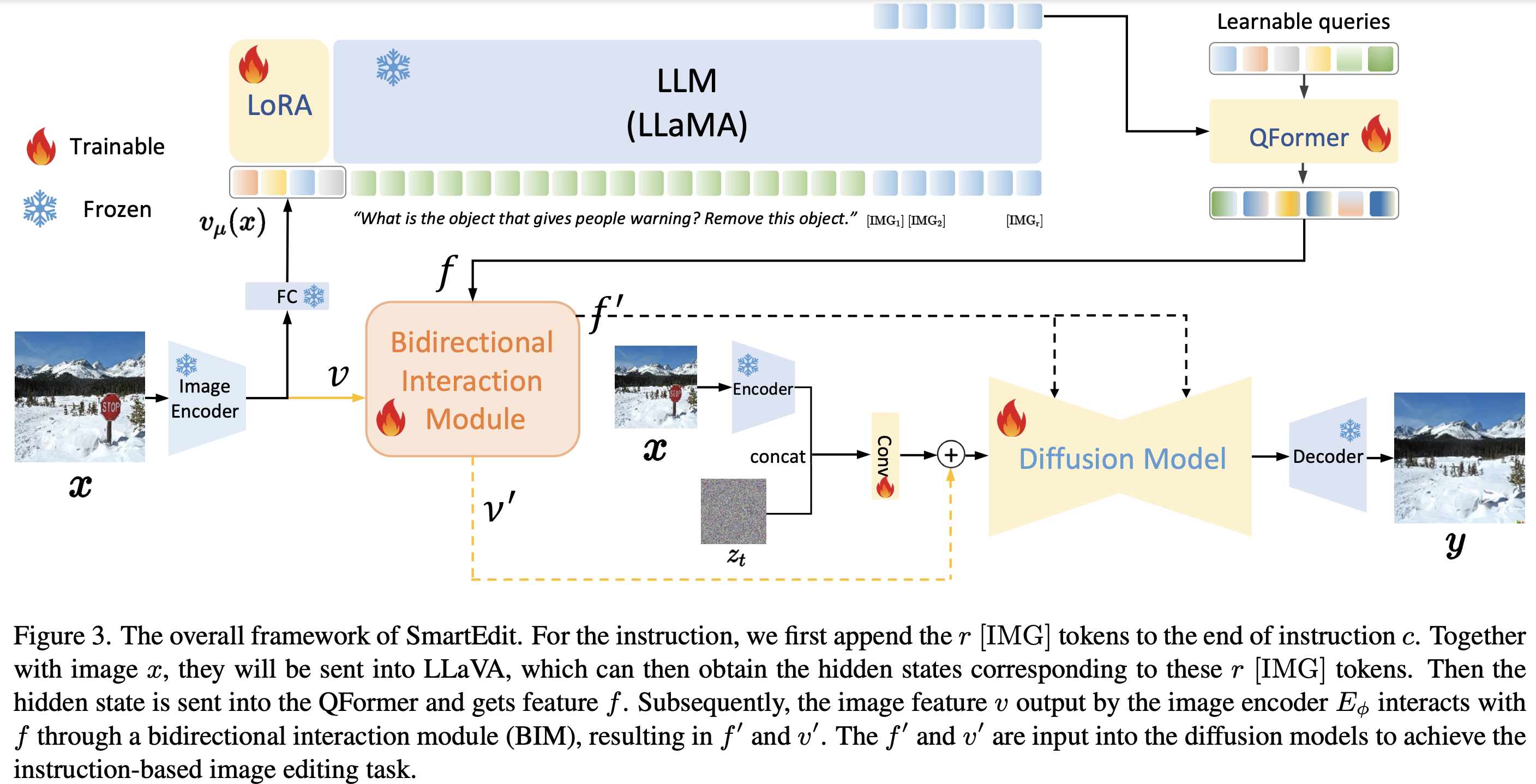
Current instruction-based editing methods, such as InstructPix2Pix, often fail to produce satisfactory results in complex scenarios due to their dependence on the simple CLIP text encoder in diffusion models. To rectify this, this paper introduces SmartEdit, a novel approach to instruction-based image editing that leverages Multimodal Large Language Models (MLLMs) to enhance their understanding and reasoning capabilities. However, direct integration of these elements still faces challenges in situations requiring complex reasoning. To mitigate this, we propose a Bidirectional Interaction Module that enables comprehensive bidirectional information interactions between the input image and the MLLM output. During training, we initially incorporate perception data to boost the perception and understanding capabilities of diffusion models. Subsequently, we demonstrate that a small amount of complex instruction editing data can effectively stimulate SmartEdit’s editing capabilities for more complex instructions. We further construct a new evaluation dataset, Reason-Edit, specifically tailored for complex instruction-based image editing. Both quantitative and qualitative results on this evaluation dataset indicate that our SmartEdit surpasses previous methods, paving the way for the practical application of complex instruction-based image editing.